首页
新闻动态公司动态 正文
SpeedyCloud李雨来:云上的DOCKER精细化运维
2015-04-23 10:15:154月10日,在51CTO 传媒的“2015互联网运维与开发者大会”上,来自SpeedyCloud迅达云 的首席架构师李雨来同学完成了一场精彩的技术演讲——“云上的 Docker 精细化运维”,内容详实,干货多多,现特别整理出来演讲稿,供运维和 Docker 爱好者参考。

4月10日,在51CTO 传媒的“2015互联网运维与开发者大会”上,来自SpeedyCloud迅达云 的首席架构师李雨来同学完成了一场精彩的技术演讲——“云上的 Docker 精细化运维”,内容详实,干货多多,现特别整理出来演讲稿,供运维和 Docker 爱好者参考。
作为运维技术人员,最关注的是什么?无非是以下四点:
•性能:系统的整体性能表现。
•资源使用监控:系统底层基础设施,包括网络、存储、计算的使用情况都要了解,以提前发现可能出现问题的地方,及时做出预防措施。
•网络:在我们这块神奇的土地上,网络是尤为神奇的领域,各个不同的互联网服务提供商之间的互相接入,不同机房的数据交换,难以预估的网络故障和抖动,都使得针对网络的处理成为重中之重。
•自动化:有数据统计,愚蠢的人为错误,占数据中心故障率的70%。运维是一项复杂而又重复性强的工作,比起机器而言,人在处理类似事务时更容易犯错,因此必须以自动化方式,让机器做重复性强的工作,把人解脱出来,从事更具开创性、经验性的思考。
面对繁杂的运维设施,干运维的总会经历这样一个心路历程:从不爽到改造,改造完了就舒服啦。当然,生活,就是一个问题接着另一个问题,运维也是这样,当我们改造了一个不爽,新的不爽又会出现。特别是在飞速发展的 Docker 这个领域中,我们接下来先谈谈如何改造 Docker 的网络。
Docker 网络部分的改造
随着使用 Docker 的人越来越多,Docker在网络方面的缺陷愈加明显。其默认的网络模式有如下三大问题:
1.网络能力不足,不支持复杂设置
2.存在性能问题
3.不易扩展
正是由于这些问题的存在,才引发了为数众多的 Docker SDN 项目,比如 pipework、weave、flannel 等等。下面简单介绍几个。
·pipework 是解决 Docker 容器互联的一个工具脚本,基本思路是把 Docker 挂载到主机上的另外一个网桥(非 Docker 自用的网桥),或者物理网卡设备上,并指定一个新的IP地址。如果两台主机之间的网桥或者物理网卡设备可以互通,那么两台主机上的Docker 容器就可以相互访问。
·Kubernetes 是由 Google 推出的针对容器管理和编排的开源项目,它让用户能够在跨容器主机集群的情况下轻松地管理、监测、控制容器化应用部署。
·Weave 能够创建一个虚拟网络来连接部署在多台主机上的Docker容器,同时还能够穿透防火墙并运行在部分连接的网络上。另外,Weave的通信支持加密,所以用户可以从一个不受信任的网络连接到主机。
·Flannel 是由 CoreOS 团队针对Kubernetes设计的一个覆盖网络工具,其目的在于帮助每一个使用 Kuberentes 的 CoreOS 主机拥有一个完整的子网。
那么,Docker 的网络改造可以从哪里入手呢?主要是以下四个部分。
·OpenVSwitch(或者 Linux Bridge)
·iproute2
·Linux Net Namespace
·Docker
我们来看看具体做法:
代码:
#!/bin/bashPID=`docker inspect -f '{{.State.Pid}}' $1`ID=`docker inspect -f '{{.Id}}' $1`ETHNAME=$2ln -s /proc/$PID/ns/net /var/run/netns/$IDip link add dev $ETHNAME.0 type veth peer name $ETHNAME.1ip link set dev $ETHNAME.1 netns $IDip link set dev $ETHNAME.0 upip netns exec $ID ifconfig $ETHNAME.1 $3 uprm -rf /var/run/netns/$ID`
使用方法:network.sh docker-test veth0 192.168.1.100/24
上述代码的主要目的和步骤如下:
每个Docker启动之后都会有一个进程,Docker会为这个进程创建自己专用的Namespace,可以通过/proc/PID/ns/路径来访问对应的Namespace。这里我们主要是使用网络的Namespace:/proc/PID/ns/net
iproute2工具提供了管理网络Namespace的功能,为了让iproute2能访问到Docker Container的网络Namespace,我们需要把网络Namespace对应的文件链接到/var/run/netns/路径下,并起一个名称(比如Docker ID)。
接下来可以使用iproute2命令来创建veth网卡并把网卡绑定到Docker Container对应的网络Namespace中即可。
当以上步骤完成之后,我们在宿主机层面可以看到一个连接到Docker Container的网卡。接下来就可以交给OpenVSwitch了。
通过上述方法,我们把传统的Docker网络模型(图1),改造成了新的网络模型(图2)
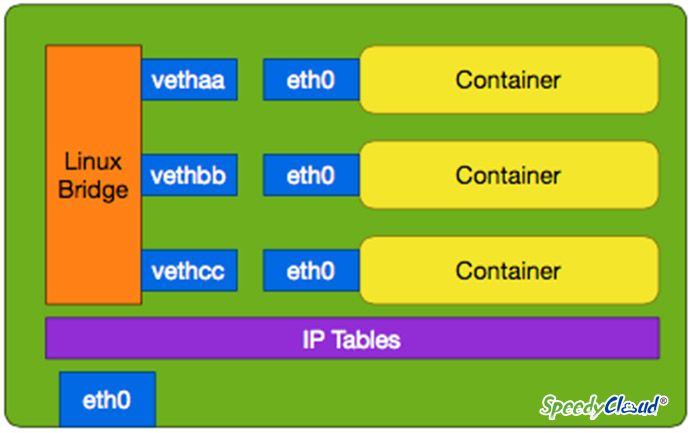
图1

图2
如此改造之后,大家就可以发挥自己的想象力了:
1.通过OpenVSwitch配置OpenFlow规则
2.如果需要高性能低延迟,可以使用SR-IOV,直接把虚拟网卡绑定到对应的Container中
3.如果需要网络隔离,那么可以使用VLAN,NVGRE,VXLAN等等
4.如果你想,可以试试跟OpenStack的Neutron结合看看。
Docker的资源隔离改进
Docker 之所以这么火爆,与其便捷的资源轻型隔离能力很有关系,但是这方面还不完善,某些效果还不如虚拟机方式的隔离。如果某个容器的 CPU、磁盘 IO、网络资源、磁盘容量使用过多,都会影响到其他容器的运行。
接下来,我们看看如何改进 Docker 的资源隔离能力。首先我们需要先了解一下 Docker针对 cgroup的管理模型:
1. 针对Libcontainer用户,Docker针对cgroup的管理模型为:
/sys/fs/cgroup//docker/
2. 针对Linux Container用户,cgroup的管理模型为:
/sys/fs/cgroup//lxc/
如果需要启动Swap的cgroup限制,可以在 Kernel 的启动参数上,也可以做些小动作,加入:
cgroup_enable=memory swapaccount=1
首先我们来看看CPU 和内存限制:
1.cpuset.cpus 指定容器使用哪几个CPU
2.cpu.shares 指定一个相对的权重来区分不同Container在使用CPU时的优先级
3.memory.memsw.limit_in_bytes 内存+Swap的上限值
4.memory.limit_in_bytes 内存的上限值
针对内存上限值的设置,我们可以参考下面的公式:
memory.memsw.limit_in_bytes = memory.limit_in_bytes + Swap Size
接下来看看磁盘 IO 的限制:
cgroup在磁盘IO方面的限制方式有两种,一种是一权重方式区分各个Container的权重,另外一种是直接限制Container的IO吞吐量和IOPS。我们主要介绍第二种方式:
1.blkio.throttle.read_bps_device 设置针对某个设备的读IO吞吐量
2.blkio.throttle.write_bps_device 设置针对某个设备的写IO吞吐量
3.blkio.throttle.read_iops_device 设置针对某个设备的读IOPS
4.bloio.throttle.write_iops_deivce设置针对某个设备的写IOPS
在设置这些cgroup参数时有一个统一的格式:
major为磁盘设备的主要编号,minor为次要编号,limit为上限值。磁盘的主要和次要编号可以通过/proc/partitions 文件查到。另外还有一个需要注意的地方是:当设置IO限制时要用磁盘设备的主要和次要编号,而不是分区的主要和次要编号。
然后我们看看网络带宽方面的限制:
其实这块的内容跟cgroup就没什么太大关联了,这里的主角其实是Linux提供的tc工具,如果使用OpenVSwitch,那么可以使用OVS自带的命令来设置网络的带宽:
ovs-vsctl set interface veth1 ingress_policing_rage=1000
最后我们来看磁盘容量限制:
在磁盘容量限制方面还是比较麻烦的,由于Docker支持使用--volume参数来挂载Container镜像之外的一个路径,如果在Container完全自己可控的情况下,使用LVM创建一个卷,在宿主机挂载之后通过--volume参数让Container通过指定的路径访问到这个卷就可以限制住Container的磁盘容量了。
那么如果想给Container镜像本身加一个Quota的话,有什么好办法么?答案是有,但有点代价:使用btrfs
其实Docker本身是支持btrfs文件系统的,而且Docker有着一套自己定义好的btrfs文件系统的管理模型,每个Container创建之后,会在btrfs文件系统中创建两个subvolume:
1./var/lib/docker/btrfs/subvolumes/CONTAINER_ID-init
2./var/lib/docker/btrfs/subvolumes/CONTAINER_ID
我们只需要给第二个不带“-init”的subvolume加入quota限制即可:
btrfs qgroup limit -e 100G /var/lib/docker/btrfs/subvolumes/CONTAINER_ID
无监控,不运维:容器的监控
Docker容器的监控,主要是针对如下指标:
1.CPU: cpuacct.usage Container的CPU使用时间,单位为ns
2.内存:
a)memory.usage_in_bytes 内存使用量
b)memory.memsw.usage_in_bytes 内存和Swap的使用和
3.磁盘IO:
a)blkio.throttle.io_serviced 分设备的IOPS统计
b)blkio.throttle.io_service_bytes 分设备的IO吞吐量统计
4.带宽:/sys/class/net//statistics/ 获取网卡信息的路径
另外,Docker还提供了一个docker stats 命令,可以用来在宿主机上实时监控Container的资源使用情况。如果读者有兴趣翻翻Docker的源码的话,这个命令其实就是使用了上面讲的4个资源监控数据源。

SpeedyCloud李雨来在演讲中
总结
Docker 在近两年的快速发展,吸引了业界众多知名大牌厂家的支持,包括亚马逊、Canonical、谷歌、IBM、 Microsoft、New Relic、Red Hat和VMware,只要有Linux,Docker几乎随处可用。还有许多初创企业也围绕着Docker发展,包括 SpeedyCloud。所有这些合作伙伴推动着核心项目和周边生态系统的快速发展。发展这么快,自然有其不完善的地方,本文就是试图从精细化运维的角度对 Docker 做出一些改进,希望能对大家有所帮助,同时也希望跟大家就该话题深入交流。

