SegmentFault D-Day北京站:SpeedyCloud董伟分享《云平台资源调度系统的进化过程》
2015-08-30 07:50:00
引子
8月29日SegmentFault D-Day北京站在天使汇DotGeek咖啡举办。本次沙龙邀请到SpeedyCloud CTO 董伟,全程围绕《面向云平台集群管理及与云应用案例》主题进行分享。
下面是我们公司 CTO 董伟的演讲内容:
内容简介
大规模的公有云计算平台管理着成千上万台物理设备,支撑着公司的多条产品线正常运行,面对分布在全球的云计算节点以及不同类型的客户对于弹性资源的需求,如何高效、稳定的将云计算资源调度到合适的节点,快速的将资源分配出来送到用户手中?这些都是资源调度系统需要解决的问题,希望通过本次分享能为大家提供一些可供借鉴的经验。
演讲正文
开篇
大家好,我发现大家学习的热情跟今天的天气一样热,整个会场都坐满了。先做个自我介绍,我是迅达云成的CTO,也就是最高级别的码农,在公司负责云计算平台的搭建,平时还负责给身边的程序猿们打打杂。

刚才听了大家的内容,都好高大上,瞬间让我觉得压力好大呀,因为现在的这版 PPT 是这周才写好的,上一版本被我们的 Warren同学给否了,我又痛定思痛重新写了一版。所以从这里也看出了 SegmentFault 同学对工作的认真和我的更认真 :)。

但是写着写着发现原来的那个主题不太贴切了,但是为了向后兼容,我就保留了这个主题,但是我想我接下来要讲的主题或许改成这个更贴切:云计算平台资源调度系统的进化过程。
之所以要讲一下进化过程,是想为大家展示一个从易到难的发展过程,因为对于很多没有从事云计算行业的同学来说,都觉得云计算是一个特别神秘特别高大上特别那什么的领域,而且像 OpenStack 这样的云计算平台开源框架,已经基本上把目前所有主流的 IT 厂商都勾引进去了,像戴尔、思科、红帽、IBM、华为等等等等。
但其实云计算行业经过了从概念期到落地出产品到现在基本上技术已经趋于稳定的发展过程,其实已经没有那么神秘了。所以今天就想跟大家一起,以一个云计算中的调度系统的小模块为例子,跟大家一起来看下,你会发现其实也不那么神秘。
什么是调度系统?
先来看一下什么是调度系统,在交通系统里,这就是一个调度平台,在这里能够看到哪条路比较拥堵,也就可以派交警过去或者对红绿灯进行一些控制,从而让行车速度从5公里每小时提升到10公里每小时。 ^_-
云计算平台的资源调度系统是干什么的呢?

那就得先看看云计算平台上都有哪些内容需要调度了:
可以看到有很多产品需要进行调度,不光有最基础的云主机、云存储,还有SDN、防火墙、负载均衡等等。
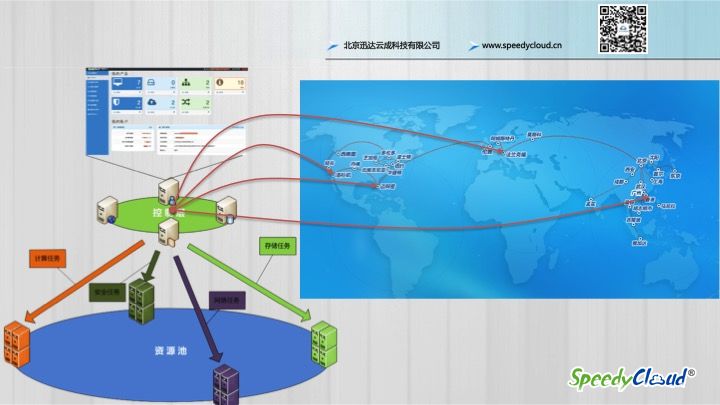
对于用户来说,云平台就是一个分布式的资源池,它上面的资源分布在世界各地。而云平台的资源调度系统就是把用户需要的资源,通过一些合适的策略及手段,把它分配到合适的地方上去,这样就完成了一个调度的过程。
云计算的资源调度系统是怎么干的?

罗马不是一天建成的,系统不是一天写好的。
任何一个完善的系统,都会经历一个迭代并不断演进的过程,都是从第一行代码开始写起的。
所以我今天试着跟大家分享一下我们的调度系统的演进过程,从头开始,咱们一起拆开看看它是如何进化的:
场景一
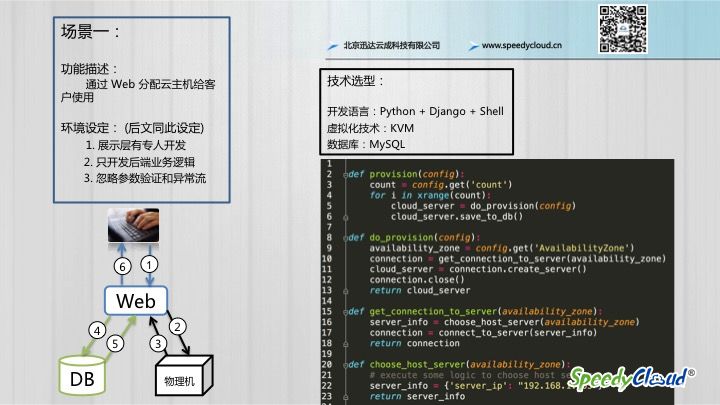
第一个场景,我为大家演示一个最简单的用户需求:
用户通过 Web分配一台云主机使用
为了更清晰的展示业务主逻辑,所以我们做了这样的环境设定(后文同此设定):
- 展示层代码由专人开发,所以不进行展示
- 只展示后端的业务主逻辑
- 忽略参数验证和异常流处理
这个分配的过程如上图所示,具体过程如下:
- 用户登录 Web 管理后台,发出云主机创建请求
- Web控制台连到一台物理机上
- 物理机分配好一台虚拟器后,返回到Wed控制台
- Wed控制台把相关信息存到数据库
- 数据保存完成后返回 Wed 控制台
- Web 控制台将分配好的设备返回,用户拿到设备
大概就是这样一个过程,用代码表示出来整个逻辑大概就是这样的:
def provision(config):
count = config.get('count')
for i in xrange(count):
cloud_server = do_provision(config)
cloud_server.save_to_db()
def do_provision(config):
availability_zone = config.get('AvailabilityZone')
connection = get_connection_to_server(availability_zone)
cloud_server = connection.create_server()
connection.close()
return cloud_server
def get_connection_to_server(availability_zone):
server_info = choose_host_server(availability_zone)
connection = connect_to_server(server_info)
return connection
def choose_host_server(availability_zone):
# execute some logic to choose host server
server_info = {'server_ip': "192.168.1.105"}
return server_info
这个阶段最显著的特点就是:Web直接跟物理机建联,然后通过执行 Shell 命令进行资源分配。
当然这个阶段只是在实验室里进行的,在这里通过简化的模型,以单机的方式,只是为了向大家展示这个最简单的过程。
场景二
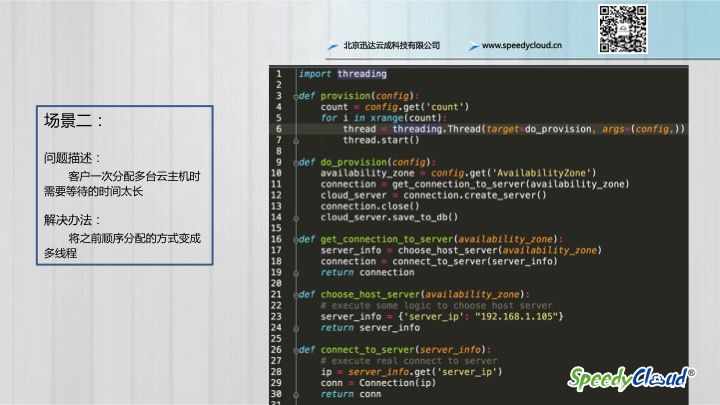
经过第一场景,客户已经可以分配一台云主机了,但是很快,新问题就来了:
客户一次分配多台云主机时需要等待的时间太长了
问题的根本原因是,如果分配多台主机的话,按照之前的逻辑,需要循环多次,并且是顺序执行,所以很自然的就想到了,将这个过程变成多线程的方式,于是基于这个思路又改了一下代码,引入了threading包,代码变成了下面这样,改完之后,快多了,妈妈再也不用担心我的速度了。
import threading
def provision(config):
count = config.get('count')
for i in xrange(count):
thread = threading.Thread(target=do_provision, args=(config,))
thread.start()
def do_provision(config):
availability_zone = config.get('AvailabilityZone')
connection = get_connection_to_server(availability_zone)
cloud_server = connection.create_server()
connection.close()
cloud_server.save_to_db()
def get_connection_to_server(availability_zone):
server_info = choose_host_server(availability_zone)
connection = connect_to_server(server_info)
return connection
def choose_host_server(availability_zone):
# execute some logic to choose host server
server_info = {'server_ip': "192.168.1.105"}
return server_info
def connect_to_server(server_info):
# execute real connect to server
ip = server_info.get('server_ip')
conn = Connection(ip)
return conn
场景三
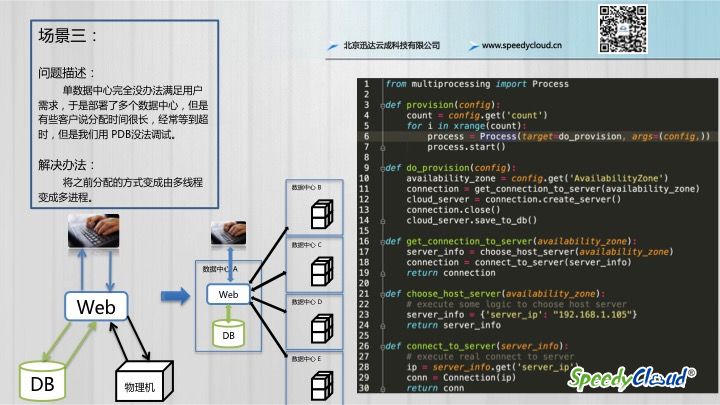
经过了上一个阶段,其实分配速度慢的问题已经解决了,但是,新的挑战总是存在的:
用户从现在开始不局限于只购买一个地方的机器了,他想买北京的、香港的,甚至是我们国外节点的设备。
于是我们就把系统扩成了上面的样子。对于程序来说,其实仅相当于由一台物理机扩展成多台,以前那个流程还是可以跑通的。
但是经常有用户说分配时间很长,有时候会分配失败,而且当我们用PDB Attach 到主进程上去调试时,发现很难进行,因为是多线程的环境,所以我们临时想了一个解决办法,先把多线程换成多进程,看看到底问题出在哪儿了。于是进行了一个简单的改造,将之前的threading 包,变成了multiprocessing,程序就变成了下面这样:
from multiprocessing import Process
def provision(config):
count = config.get('count')
for i in xrange(count):
process = Process(target=do_provision, args=(config,))
process.start()
def do_provision(config):
availability_zone = config.get('AvailabilityZone')
connection = get_connection_to_server(availability_zone)
cloud_server = connection.create_server()
connection.close()
cloud_server.save_to_db()
def get_connection_to_server(availability_zone):
server_info = choose_host_server(availability_zone)
connection = connect_to_server(server_info)
return connection
def choose_host_server(availability_zone):
# execute some logic to choose host server
server_info = {'server_ip': "192.168.1.105"}
return server_info
def connect_to_server(server_info):
# execute real connect to server
ip = server_info.get('server_ip')
conn = Connection(ip)
return conn
经过调试,我们很快的发现,执行任务不成功是因为某些数据中心到控制中心的网络不是很稳定,实际上云主机已经分配成功了,但是控制中心没拿到状态。
场景四
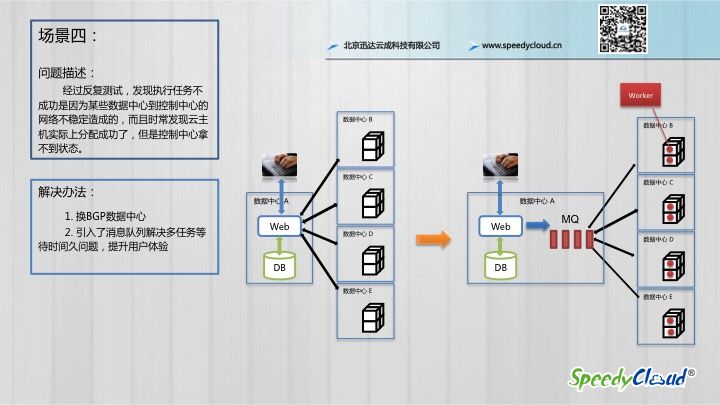
像这种跨网和跨数据中心的操作,对网络的稳定性要求就变高了,因为大家知道中国的网络状况非常复杂,运营商之间的出口及连接速度不是特别理想。
遇到这种情况,其实问题就和程序的关系不是很大了,但是有些很理想的开发者坚持认为可以通过一些特殊的手段可以解决掉,例如多点接入、运营商适配、做智能路由等等,但其实最终你会发现用程序很难突破这种物理上的限制,即使最终费大力气搞定了,那么系统的复杂度恐怕高到一个很难控制的地步,所以这里存在一个平衡。
其实最快最利索的方式就是把控制中心换到更好的BGP机房里去,这可能也是很多程序员思维上易陷入的误区。
正如当初我还是一名程序员的时候(其实现在也还是程序员,要写代码),认为程序可以搞定一切,但是后来我发现当你遭遇物理瓶颈时,比如说对于数据库,我经过各种的优化,建索引、分库、分表,消除慢查询,还是没搞定查询慢的问题,找到运维,运维给换了SSD的硬盘就搞定了,多么痛的领悟啊!
解决了网络链路的问题之后,其实还有一个问题没有解决:
到目前为止所有的操作还都是按顺序执行的,也就是说系统要等到最慢的那个成功返回了,才会将执行状态返回给客户,这对于那些一下子要分配很多不同地区的资源的用户是完全不可接受的,体验很差。
于是,为了提升这部分用户的体验,我们引入了消息队列,用它来实现用户请求和响应的异步机制,这样做了之后,当用户提交分配资源的请求之后,不用等到执行成功就可以立即反馈给用户执行情况,我们会将资源分配状态进行区分,比如申请已提交、分配中、分配成功、分配失败等。这样,用户就可以实时的知道各个任务的执行状态了。

完成了这部分改造之后,基本上用户体验就变得非常的好了,大家都觉得松了一口气,可以做一些别的事了。不过,新的挑战一定还会有,我们整装待发,准备迎接下一阶段的挑战。
场景五
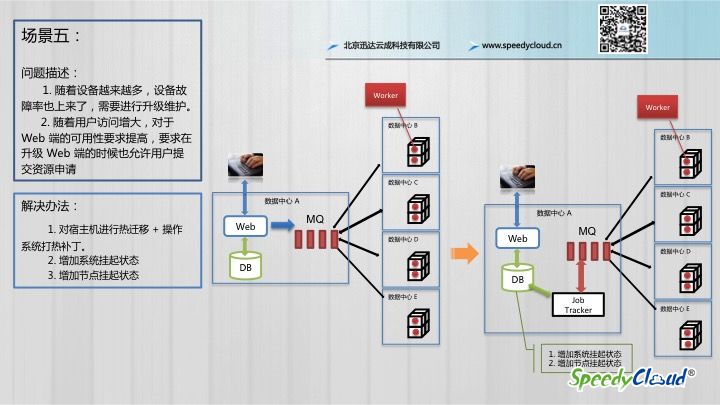
新的问题会随着业务规模的不断扩大而出现:
- 随着我们的设备越来越多,故障率也会上升,需要进行升级维护。
- 随着用户访问增大,对于 Web 端(也就是平台端)的可用性要求提高,要求在升级平台的时候也允许用户提交资源请求。
解决第一个问题
像BAT这样的公司应该深有体会,当设备达不到一定的量级后,设备出故障就是一种常态,所以经常需要去维护或者更换。对于这种情况我们的处理办法是:
- 在接到宿主设备告警后,我们首先将该节点挂起,我们在 DB 上对该节点增加了挂起状态,挂起的节点就会被踢出资源池。
- 将宿主设备上的云主机进行热迁移,迁移到其他的物理机上面去,这个迁移对用户来说是无感知的。
- 对告警设备进行维护
解决第二个问题
为了不中断用户的资源提交请求,我们在对系统进行维护的时候,会在数据库中增加一个平台的挂起状态。这也得益于我们之前采用了消息队列的方式,消息再被推送之前其实是先进入到数据库里面的,是一条任务消息,那么当 JobTracker 检测到平台状态是挂起的时候,他就不会再往我们的消息队里中增加任务,需要等到整个平台解除挂起状态之后才会继续执行,这就实现了一个升级平台不中断用户请求的功能。
写在最后的话

这就是我们的资源调度系统的一个简单的演化过程,总体看来,不是特别的复杂,重要的在于我们不断的根据客户和业务需求对整个系统做调整和完善,更多的体现的是一种迭代的思想,一种不断探索和创新的过程,希望这一个过程能给大家提供一些借鉴的意义,也希望大家能从中受到鼓舞,不断的对自己的系统进行优化和改进。
最后,希望大家关注我们SpeedyCloud迅达云,希望我们的努力能加速大家的成功。

